Before this, Workera could only take one snapshot of a skill. Ever.
No retakes. No remeasurement. No way to answer whether someone had actually improved. Designing the system that replaced a fixed score with a real trajectory, from zero.
Designing this required co-defining the model itself alongside the tech lead, the principal product designer, and the CPO. Before any screen existed.
One score. One point in time. No way to say it changed.
Every capability in Workera could be assessed once. No retake, no remeasurement, nothing. For program leaders and admins running learning initiatives at scale, this made the platform unable to answer its most basic question: is this person actually improving? One score, fixed at a single point in time, with no path to update it.
Reassessment didn't exist. There was no flow to fix, no screen to improve. The first decision wasn't how to design it. It was what it should even be.
My scope
Co-defined the core model alongside the tech lead, the principal product designer, and the CPO. These were decisions about how the product measures skill development across an entire platform, not how one screen should look. From there, I owned the design across three audiences: how leaders configure a program's progress settings, how participants discover and take a reassessment, and how managers read the results. I ran the competitive research that shaped several of these decisions using a Claude skill I built myself, and contributed to usability testing with ListenLabs.
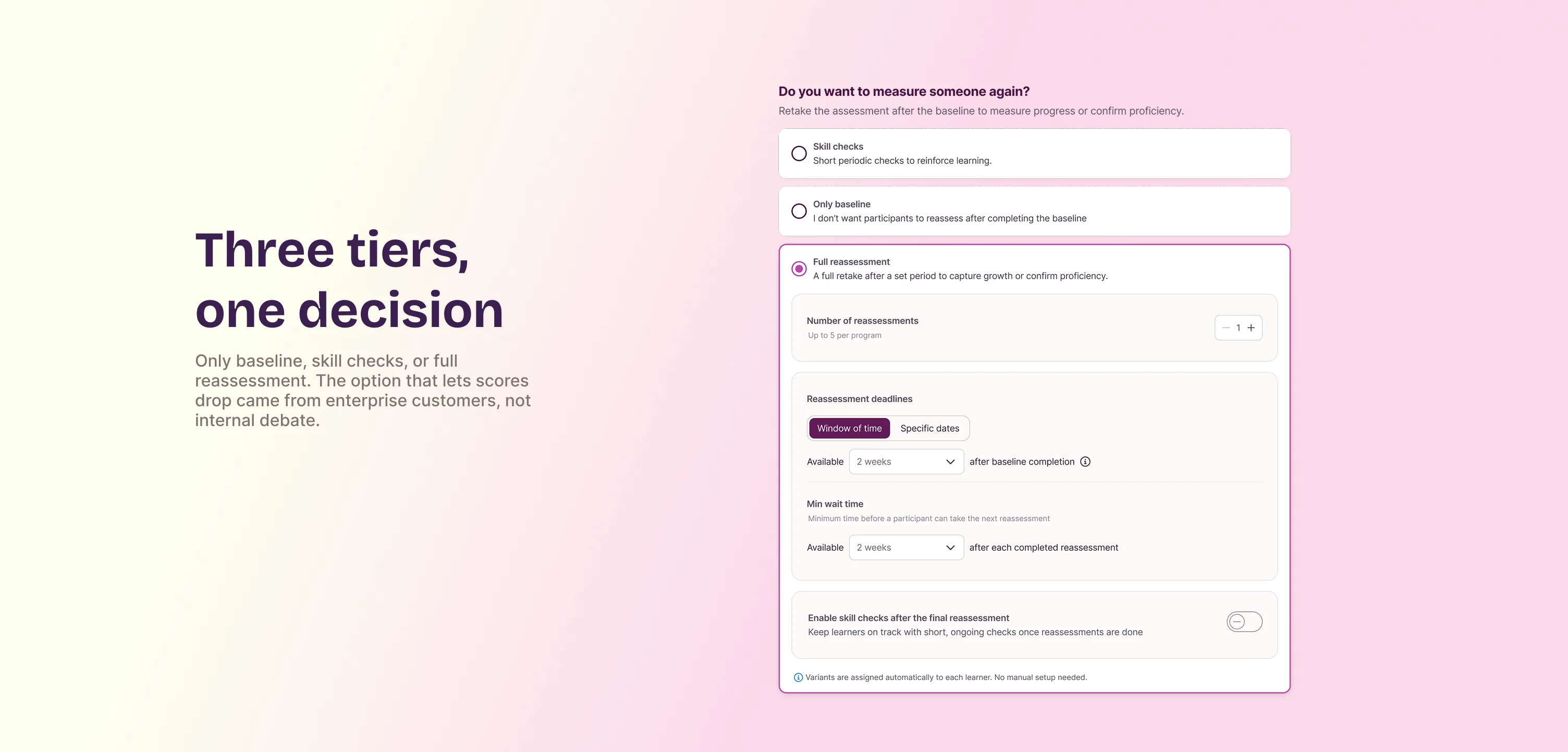
Three tiers, because one size fits nothing
We defined three options a leader can choose when setting up a program:
- Only baseline. No progress measurement. One assessment, nothing after it.
- Skill checks. Short, frequent activities where the score can only go up. Built for momentum, not formal evaluation.
- Full reassessment. A complete remeasurement with new question variants generated by AI, where the score can go up or down. This is the only level that reflects what someone actually knows now, not just what they've added since the baseline.
This was a values question before it was a product question: do you tell someone their skill went backwards? I brought the answer from enterprise customers, not from internal preference.
Whether scores should be allowed to drop in full reassessment was debated internally, the concern being that a lower score feels like a failure. Direct discovery with enterprise customers, including a global consultancy and a Fortune 500 tech company, settled it: they needed exactly this range of options. A score that can only go up doesn't measure progress, it measures activity, and enterprise customers understood that difference immediately.
I built the research tool before I ran the research
To inform this, I built a Claude skill tailored to Workera's market and used it to analyze how 8 competitors handle retakes, cooldowns, and score history (Pluralsight, Skillsoft Percipio, iMocha, CodeSignal, HackerRank, TestGorilla, Degreed, and LinkedIn). The output became an internal brief I shared with stakeholders.
Two findings shaped the design directly: most platforms let a new score replace the old one with no record of where someone started. We avoided that deliberately. And only one competitor separates an informal check-in from a formal, certifiable retake. We adopted that split, but tied it to Workera's own skill development ecosystem in a way no competitor's model can match.
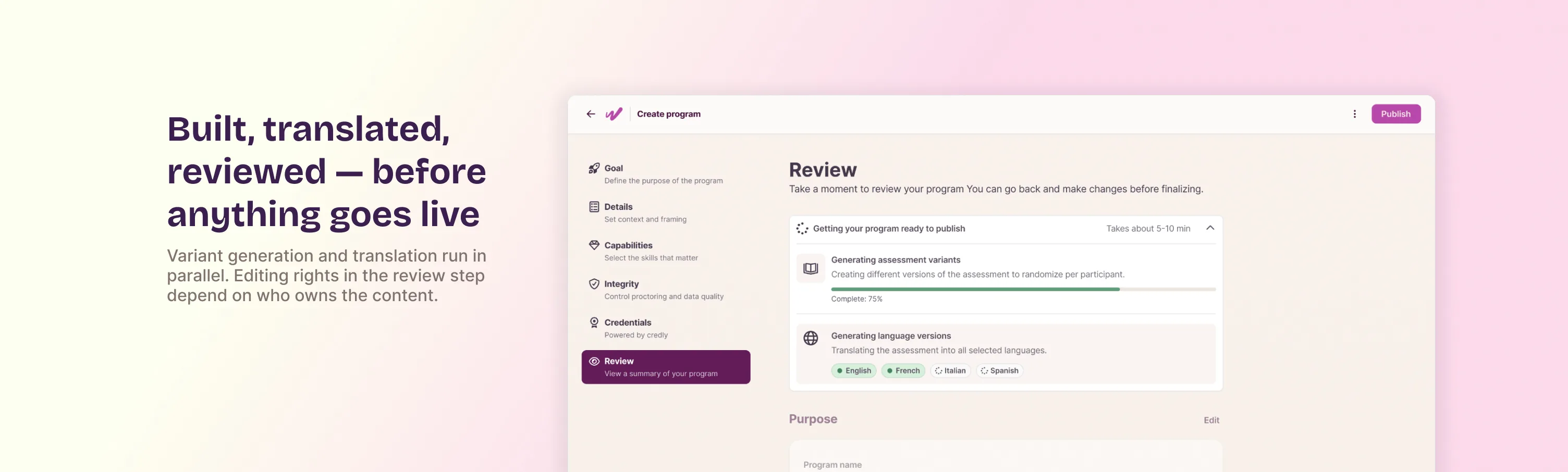
AI generates the questions. Admins decide if they trust them.
Full reassessment needs new question variants so it isn't just a repeat of the original. Generating them takes a few minutes, so I designed a loading state showing two processes running side by side: generating the assessment variants, and translating them into every language the program supports. Then a review step for admins before the program goes live.
How much an admin can edit in that review depends on what they're reviewing. For custom capabilities, they can edit the variants the model produced. For Workera's own curated capabilities, the content is locked. It's a third version of a question that runs through my work at Workera: how much should people trust what a model produces? Here, the checkpoint sits before publication rather than after a dispute, and the trust boundary depends on who owns the content.
The same review screen also surfaces Workera's AI usage detection settings, monitoring for AI tool access and flagging unusual typing patterns. The platform that generates assessment content with AI is also the one watching for AI use during the assessment itself.
The first design for surfacing a reassessment: a banner nobody saw
Usability testing with ListenLabs and 20 participants validated the core assumption: people could see their progress across assessments. The same testing also killed the first design for surfacing a reassessment. A banner at the top of the homepage went unnoticed. It was replaced with a dedicated "Up next" section listing each upcoming reassessment with a countdown, paired with a reminder email, since most participants don't come back to Workera on their own after finishing an assessment.
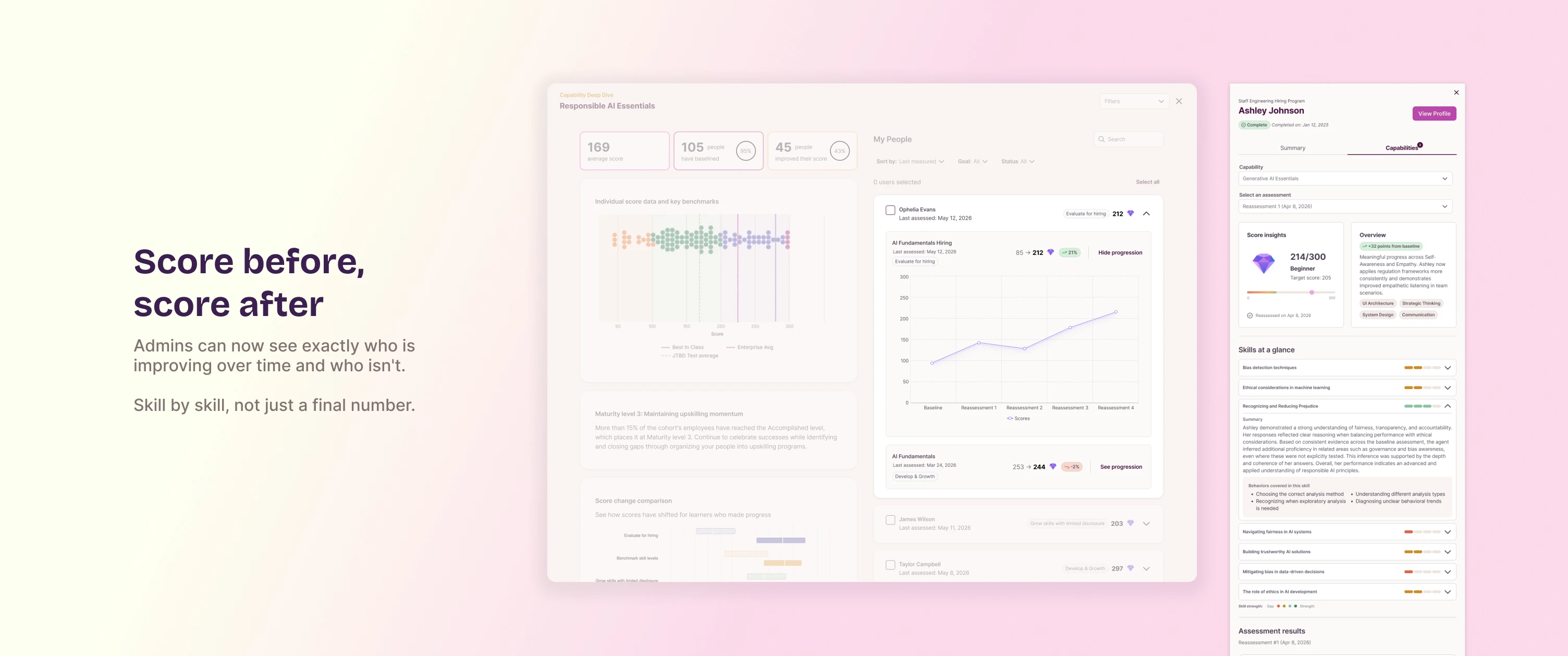
The correctness pattern from Case Study 2 (correct or incorrect badges plus a skill-by-skill breakdown) reappears here too, in the manager's view of a participant's reassessment results.
Prototype used in testing View participant flow →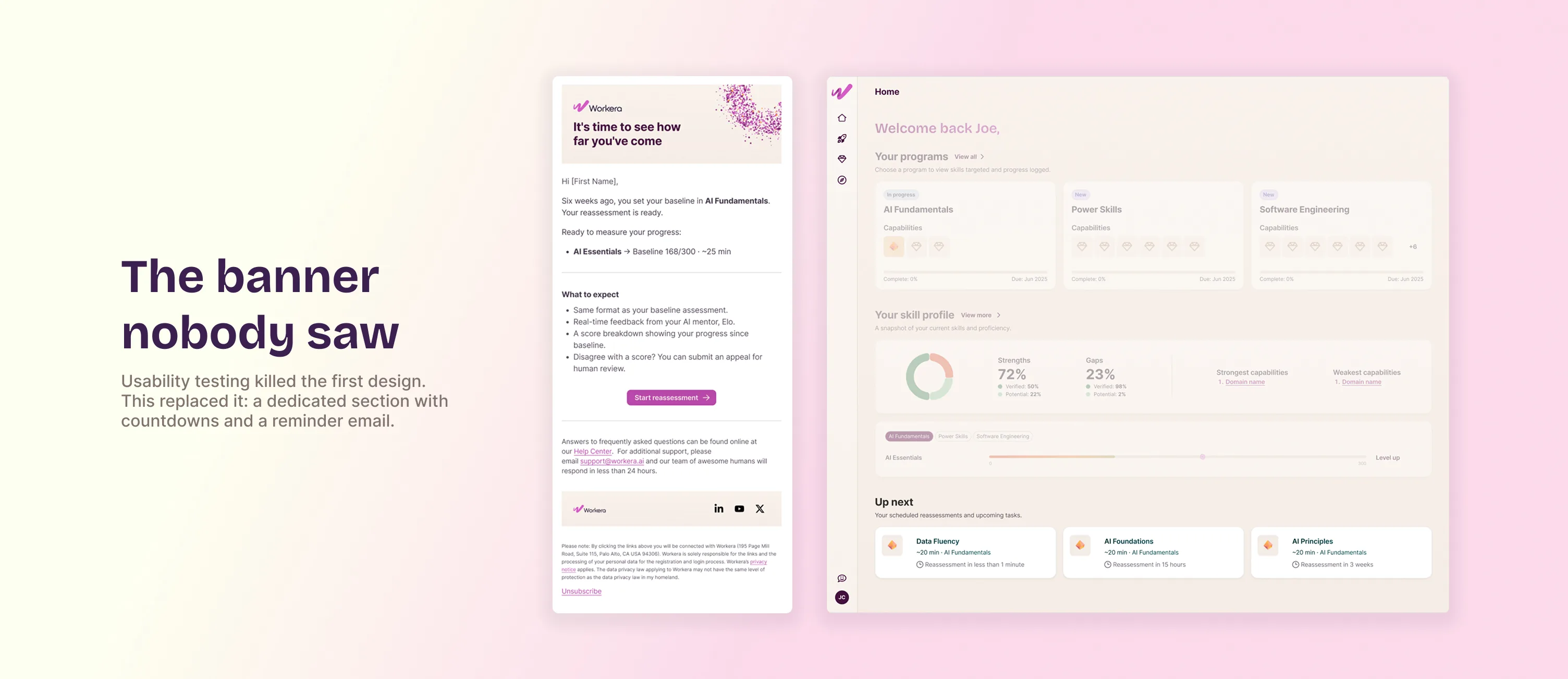
Still in development when I left. Here's what's real.
This was still in active development when I left Workera, so there's no production data. What exists is the usability testing: 20 participants confirmed they could read their own progress, and that same round is the reason the homepage shows a scheduled "Up next" list instead of a banner nobody saw. The testing didn't validate the design. It changed it.
What I take from this
Designing something that doesn't exist yet requires a different kind of judgment than redesigning something that does. The questions shift from "how should this work better" to "what should this even be" and "who is it actually for." Those decisions happened at the level of the model, not the UI.
- Built a capability that didn't exist and co-defined the model it runs on. The three-tier structure was a decision about what the product measures, made alongside the tech lead, the principal product designer, and the CPO. That's a different problem than redesigning something broken.
- Resolved an internal debate on whether scores can drop with direct evidence from enterprise customers, not internal opinion.
- Built and used my own AI tool: a Claude skill for competitive research that produced a brief shared with stakeholders and shaped real design decisions.
- A third version of the AI trust question from Cases 1 and 2: here it's a pre-publication review with editing rights tied to content ownership, placed before anything goes live rather than after a dispute.
- Usability testing that changed the product: the homepage "Up next" section replaced a banner nobody saw, because 20 participants confirmed the banner before confirming anything else.